Unturf · permacomputer.com · uncloseai.com · unfirehose.com
arborist — Merkle-Providence Reverse RAG, reference implementation#
License: AGPL-3.0-only · 2026-05-14 · Russell Ballestrini <russell@unturf.com>
Abstract#
arborist is an answer-cache for retrieval-augmented question
answering that verifies every answer against its source with a
mechanical, deterministic checker — no second AI judging the first.
Every cached answer carries a cryptographic chain back to the bytes
of the source it came from. It is the reference implementation of the
Merkle Providence Reverse RAG whitepaper
(unfirehose.com/merkle-providence-reverse-rag.html), with
a free reference inference endpoint at hermes.ai.unturf.com/v1 (OpenAI-compatible — the
/v1/models link returns the live model card); arborist also runs
against any OpenAI-compatible alternative.
What it solves#
Standard retrieval-augmented systems hand a language model some context and accept its answer. The user has no way to tell whether the answer faithfully reflects the source or whether the model improvised. arborist replaces that trust gap with a check: every answer is verified, every answer is labelled, every answer carries a proof chain back to the bytes of the source it cites.
How it works#
arborist keeps three layers in a single SQLite file. Ingested documents are split into chunks, hashed, and indexed for full-text search. Derived layers — summaries, indices, distillations — are hash-bound to the documents they came from. An answer cache stores every verified answer, keyed by the document, the question, the model that produced it, and the policy under which it was checked. Every write appends a hash-chained audit row; a single tampered record breaks the chain.
When you ask a question, arborist retrieves candidate source chunks,
tags each one with a short label (E1, E2, …), and passes them
to the language model. The model emits prose with those labels — for
example, “Jupiter is the largest planet [E1], with a radius of about
70 000 km [E2]”. The model never types the quoted text. arborist
composes the answer at display time, interpolating the actual chunk
text at each label. A class of fabrication — the synthetic quote that
looks like a verbatim citation but came out of the model’s prior —
becomes impossible by construction.
After generation, the verifier runs. Four mechanical strategies (exact-quote match, line-span match, named-entity proximity, paraphrase coverage) try in sequence to confirm each claim against the cited chunks. The output is a single label per answer: grounded (every claim verifies), partly grounded, or ungrounded. There is no “high confidence” middle ground — confidence labels are soft signals in disguise. The verifier names what it can prove and what it cannot.
What makes it different#
The verifier is mechanical, not neural. Faithfulness is a textual property of (answer, evidence, source) and is computed deterministically. No language model in the proof path means no model drift in the proof path.
The model cannot fabricate citations. arborist sits between the model’s output and the rendered answer; the model proposes references, arborist renders the content of those references from the actual source bytes.
Soft signals stay outside the proof. Embedding similarity, cross-encoder rerankers, natural-language-inference judgments — all useful, all used to find and rank evidence; none of them allowed to influence the verification label or the audit chain. The cheap, provable path ships by default; the expensive, semantic path is opt-in and additive.
Replay is free and exact. Answers are content-addressed. The same question on the same document under the same policy returns the same record, with the same proof chain. Different document, different model, or different policy yields a different cache entry. The cache partitions cleanly; the corpus stays untouched.
What you would run it for#
You hold a corpus — internal documents, public scientific literature, a legal archive, a textbook collection — and you want reliable Q&A over it without paying a closed-source vendor or wiring up a vector database. You care that the answers track your sources. You want users to be able to verify, replay, and share the proof. You want it to keep working when the model changes, when the policy changes, when the corpus version-bumps.
What it costs#
Language |
Python 3.12 |
Storage |
SQLite — one file per shard, designed around ~10 GB each. A Wikipedia-class corpus lands across a handful of shards (the live deployment is 4 × ~9.6 GB ≈ 38 GB, holding 3.5 M documents and 6.2 M chunks). |
Compute |
No GPU required for the proof path. Inference runs wherever you want — locally, or via an OpenAI-compatible endpoint. |
Optional |
Cross-encoder rerankers (80–560 MB) for harder relevance ranking. They never enter the proof. |
License |
AGPL-3.0-only |
What it has measured on real traffic#
Misattribution detection. Catches 100% of answers where the cited source is unrelated to the claim — at strictly zero false positives across the full pooled test bed (cross-encoder reranker, hard threshold, real Wikipedia-haystack questions).
Topic-deflection detection. Catches 55–65% of off-topic answers at 0–0.4% false positives, depending on the reranker model chosen (a small 80 MB model and a larger 560 MB model both clear the bar).
Citation coverage. On the curated textbook corpus, 100% of cited claims resolve to a chain of evidence ending at a public-domain or open-licensed source — eighteen textbooks plus curated cross-citation aliases.
Sample sizes are stated, sample sources are real, and the gates are reported against the same numbers an external reviewer can reproduce from the repository.
License — Permacomputer Preamble#
AGPL-3.0-only · NO WARRANTY
Free software for the public good of a permacomputer at
permacomputer.com — an always-on computer by the people, for
the people. Durable, easy to repair, distributed like tap water
for machine learning intelligence.
Four values: TRUTH · FREEDOM · HARMONY · LOVE.
Copyright (C) 2025-2026 TimeHexOn & foxhop & russell@unturf.
Full text: `LICENSE` at the repository root.
Appendix A — The three layers#
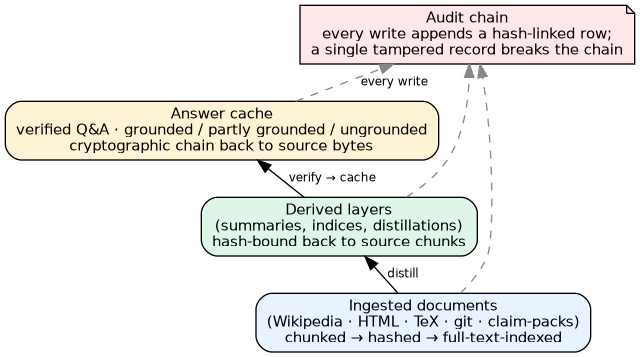
Ingested documents, derived layers, and the answer cache — each layer hash-binds to the next. Every state change appends one row to the audit chain; a single tampered record breaks the chain.#
Appendix B — How an answer is verified#

The model sees labelled source chunks and emits prose tagged with those labels — it never types the quote text. A mechanical verifier then checks every cited claim against the actual source and assigns the answer one of three labels.#
Permacomputer Preamble — License: AGPL-3.0-only
This is free software for the public good of a permacomputer hosted at permacomputer.com, an always-on computer by the people, for the people. Durable, easy to repair, & distributed like tap water for machine learning intelligence.
Our permacomputer is community-owned infrastructure optimized around four values:
TRUTH — First principles, math & science, open source code freely distributed.
FREEDOM — Voluntary partnerships, freedom from tyranny & corporate control.
HARMONY — Minimal waste, self-renewing systems with diverse thriving connections.
LOVE — Be yourself without hurting others, cooperation through natural law.
NO WARRANTY. Software is provided “AS IS” without warranty of any kind. Full text: License.